

Data Management Overview¶
Why should you care about data management?¶
If you give your data to a colleague who has not been involved with your project, will they be able to make sense of it? Will they be able to use it effectively and properly?
If you come back to your own data in five years, will you be able to make sense of it? Will you be able to use it effectively and properly?
When you are ready to publish a paper, is it easy to find all the correct versions of all the data you used and present them in a comprehensible manner?
Data management produces self-describing datasets that: - make life much easier for you and your collaborators - benefit the scientific research community by allowing others to reuse your data - are required by most funders and many journals - Recent Dear Colleague letter from NSF - NSF proposal preparation guidelines: https://www.nsf.gov/pubs/policydocs/pappg19_1/pappg_11.jsp#XID4
Data Management Basics¶
The Data Life Cycle¶
Data management is the set of practices that allow researchers to effectively and efficiently handle data throughout the data life cycle. Although typically shown as a circle (below) the actually life cycle of any data item may follow a different path, with branches and internal loops. Being aware of your data’s future helps you plan how to best manage them.
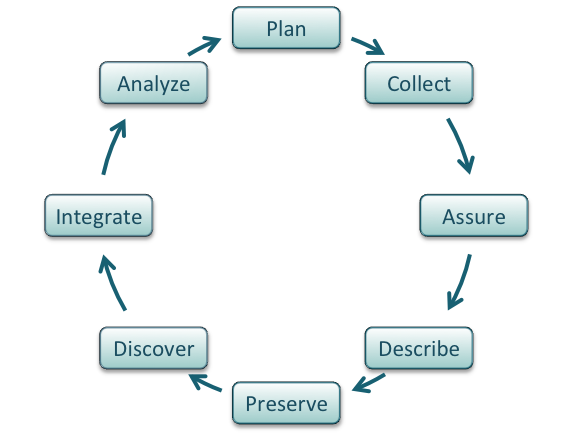
Image from Strasser et al..
Data Types¶
- Different types of data require different management practices. What are some of the considerations for managing:
- tabular data
- images
- sound or video recordings
- geospatial data
- sensor data
- raw versus processed data
- files versus datasets
Best practices for the data life cycle¶
The summary below is adapted from the excellent DataONE best practices primer.
- Plan:
- Describe the data that will be compiled, and how the data will be managed and made accessible throughout its lifetime.
- A good plan considers each of the stages below.
- Collect:
- Have a plan for data organization in place before collecting data.
- Collect and store observation metadata at the same time you collect the metadata.
- Take advantage of machine generated metadata.
- Assure:
- Record any conditions during collection that might affect the quality of the data.
- Distinguish estimated values from measured values.
- Double check any data entered by hand.
- Perform statistical and graphical summaries (e.g., max/min, average, range) to check for questionable or impossible values.
- Mark data qualtiy, outliers, missing values, etc.
Describe: Comprehensive data documentation (i.e. metadata) is the key to future understanding of data. Without a thorough description of the context of the data, the context in which they were collected, the measurements that were made, and the quality of the data, it is unlikely that the data can be easily discovered, understood, or effectively used.
- Organize your data for publication. Before you can describe your data, you must decide how to organize them. This should be planned before hand, so that data organization is a minimal task at the time of publication.
- Thoroughly describe
- the dataset (e.g., name of dataset, list of files, date(s) created or modified, related datasets)
- the people and organizations involved in data collection (e.g., authors, affiliations, sponsor)
- Go get an ORCID if you don’t have one.
- the scientific context (reason for collecting the data, how they were collected, equipment and software used to generate the data, conditions during data collection, spatial and temporal resolution)
- the data themselves
- how each measurement was produced
- units
- format
- quality assurance activities
- precision, accuracy, and uncertainty
Metadata standards and ontologies are invaluable for supporting data reuse.
- Metadata standards tell you
- which metadata attributes to include
- how to format your metadata
- what values are allowable for different attributes
- Some metadata standards
- DataCite (for publishing data)
- Dublin Core (for sharing data on the web)
- Minimum Information for any (x) Sequence (MIxS)
- OGC standards for geospatial data
- Ontologies provide standardization for metadata values
- Example: Environment Ontology terms for the MIxS standards
- Example: Plant Ontology for plant tissue types or development stages
- FAIRSharing.org lists standards and ontologies for Life Sciences.
The CyVerse Data Commons supports good data description through
- Metadata templates (remember the DataCite metadata template from yesterday)
- Bulk metadata upload (example dataset)
- Automatic collection of analysis parameters, inputs, and outputs in the DE.
- Preserve:
- To be FAIR data must be preserved in an appropriate long-term archive (i.e. data center).
- Sequence data should go to INSDC (usually NCBI
- Identify data with value – it may not be necessary to preserve all data from a project
- The CyVerse Data Commons provides a place to publish and preserve data that was generated on or can be used in CyVerse, where no other repository exists.
- See lists of repositories at FAIRSharing.org.
- Github repos can get DOIs through Zenodo.
- Be aware of licensing and other intellectual property issues
- See licensing information below
- Repositories will require some kind of license, often the least restrictive
- Repositories are unlikely to enforce reuse restrictions, even if you apply them.
- Discover:
- Good metadata allows you to discover your own data!
- Databases, repositories, and search indices provide ways to discover relevant data for reuse
- https://toolbox.google.com/datasetsearch
- https://www.dataone.org/
- FAIRSharing.org lists databases for Life Sciences.
- Integrate:
- Data integration is a lot of work.
- Standards and ontologies are key to future data integration
- Know the data before you integrate them
- Don’t trust that two columns with the same header are the same data
- Properly cite the data you reuse!
- Use DOIs wherever possible
- Analyze:
- Follow open science principles for reproducible analyses (CyVerse, RStudio, notebooks, IDEs)
- State your hypotheses and analysis workflow before collecting data. Tools like OSF allow you to make this public.
- Record all software, parameters, inputs, etc.
FAIR data¶
How to make data findable, accessible, interoperable, and reusable.
See the FAIR data page.
Open versus Public versus FAIR:
One definition of open: http://opendefinition.org/
FAIR does not demand that data be open.
References and Resources¶
- Licensing information:
- Open Data Commons <https://opendatacommons.org/licenses/index.html>-
- Creative Commons
Fix or improve this documentation:
- On Github: Github Repo Link
- Send feedback: Tutorials@CyVerse.org